
Everyone’s talking about AI. But here’s what nobody tells you — not all AI works the same way.
You’ve probably heard terms like LLM and RAG thrown around in meetings, LinkedIn posts, or sales pitches. They sound complicated. They’re not. Once you understand what each one actually does, choosing between them becomes a lot easier.
Let’s break it down. No jargon. No fluff. Just what you need to know.
How Do LLMs Work? A Beginner-Friendly Breakdown
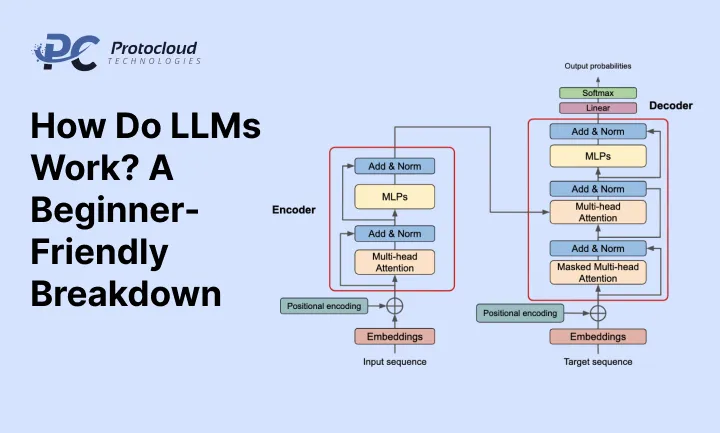
Think of a large language model like a really smart student who spent years reading everything on the internet. Books, articles, research papers, forums — all of it. By the time this student finishes “school,” they’ve absorbed a massive amount of knowledge.
LLM fine-tuning takes that already-smart student and sends them back to school — but this time, with your company’s textbooks. Your tone. Your terminology. Your specific way of doing things.
Instead of a general AI that gives generic answers, you get one that sounds like it actually works at your company.
This works best when your knowledge is stable and deep. A legal firm with years of experience in contract templates. A healthcare company with specific clinical guidelines. A support team with a very defined way of talking to customers.
The trade-off? LLM model training cost isn’t cheap. Training takes time, sometimes weeks. And every time your information changes, you may need to retrain.
What Is RAG and Why Are Businesses Loving It Right Now?

Retrieval augmented generation works differently. Instead of teaching the AI everything up front, you give it access to a filing cabinet. Every time someone asks a question, the AI opens that cabinet, finds the right document, and uses it to answer.
That filing cabinet is your knowledge base — your product docs, support articles, HR policies, compliance guides. The AI doesn’t memorize them. It just reads them on demand.
How RAG Works in Simple Steps
The RAG architecture comprises three basic parts that work together.
First, there’s a retriever that searches your documents using something called vector embeddings — basically a smart search that understands meaning, not just keywords. Second, there’s the language model that reads the retriever’s output. Third, there’s a generation layer that puts together a clear, helpful answer.
The result? Answers grounded in your actual documents. Not guesses. Not hallucinations. Real information from real sources.
LLM vs RAG: The Differences That Actually Matter

Here’s where it gets practical. When comparing fine-tuning vs. RAG, three things matter most to business owners — cost, accuracy, and ease of updating.
The cost of AI model training for fine-tuning can be high. You’re paying for compute, data preparation, and developer time. But once it’s done, the model runs fast and doesn’t need to look anything up. It just knows.
RAG vs. fine-tuning cost flips the equation. RAG costs more per query because it’s always searching. But you save a fortune on retraining. When your product catalog changes or your policies update, you swap out the documents. No retraining needed.
Accuracy is where RAG often wins for dynamic businesses. Because it’s pulling from real, verified documents, it’s less likely to make things up.
Reduce AI hallucinations — that’s one of RAG’s biggest selling points for
business-critical applications.
Fine-tuning wins when consistency is everything. If you need the AI always to sound a certain way, follow a specific reasoning pattern, or operate in a sensitive environment like healthcare or legal, a fine-tuned model is more reliable.
Real Business Situations — Which One Should You Pick?
This is where theory meets real life. If you run an ecommerce AI chatbot, your product details change weekly. Prices shift. Promotions come and go. A fine-tuned model won’t keep up. RAG does — because you update the docs, and the AI automatically gives accurate answers.
If you’re building AI in legal tech, your AI needs to think and speak like a lawyer. It needs deep domain knowledge baked in. That’s fine-tuning territory. The knowledge is stable, the stakes are high, and generic answers aren’t acceptable.
AI in healthcare often needs both. The core clinical logic gets fine-tuned for safety and compliance. RAG layers on top for accessing the latest research or patient-specific information.
For AI for customer support, RAG is usually the smarter starting point. Your support docs, FAQs, and policies live in a knowledge base. RAG connects your AI to that knowledge base and gives customers accurate, real-time answers without any retraining headaches.
RAG vs LLM Fine-tuning: When to Choose What for Your Business?

At some point, the theory stops helping, and the real question kicks in — which AI approach should your business actually use? It is not about which model sounds more impressive in a pitch deck. It is about what fits how your business runs today and how you plan to grow tomorrow. The RAG vs. LLM fine-tuning debate comes down to one core idea: are you solving a knowledge problem or a behavior problem? Get that question right, and everything else falls into place. This guide gives you the straight answer — no fluff, no jargon.
When LLM Fine Tuning Is Clearly the Right Call
LLM fine-tuning makes the most sense when your problem is about behavior, not about the freshness of information. In other words, if the challenge is getting an AI to think a certain way — to follow a specific reasoning path, produce consistent structured outputs, or speak in your exact brand voice — then fine-tuning is where you should invest your time and budget.
Take complex reasoning tasks as a classic example. If you are building something that requires multi-step logic — drafting legal documents, running complex AI workflow automation tools, or generating structured reports in a defined format — fine-tuning teaches the model how to think, not just what to say. That distinction matters enormously in high-stakes applications.
Where fine-tuning wins by a wide margin
LLM fine-tuning use cases tend to cluster around tasks that are high-volume, narrow, and repeatable. When the same task runs thousands of times per day with little variation, a well-trained, fine-tuned model performs that task predictably, quickly, and cheaply at scale. This is also where the financial benefits of fine-tuned LLMs become most obvious — the per-query cost drops significantly once the model is trained and deployed.
- AI for classification tasks — sorting documents, routing support tickets, and categorizing leads automatically without human review.
- AI for sentiment analysis — understanding customer emotion at scale across reviews, surveys, and chat logs.
- AI for data extraction — pulling structured data from unstructured text reliably and consistently.
- AI for content consistency — keeping tone, phrasing, and personality locked in across thousands of outputs, perfect for AI for brand voice management.
The other killer use case for LLM fine-tuning is when your underlying data is already clean, stable, and mature. If your knowledge base does not change much — established company policies, mature regulatory frameworks, fixed product specifications — then there is no practical need for live retrieval. Fine-tuning is more efficient, more predictable, and, frankly, more economical in these situations.
Fine-tuning is a long-term commitment. Once behavior is baked into the model, updating it requires retraining. If your information changes monthly, fine-tuning alone will create maintenance headaches in a hurry.
When RAG Is the Smarter Business Choice
RAG use cases in business almost always involve one of three things: information that changes frequently, datasets too large to train on, or situations where being wrong is genuinely dangerous. If any of those describe your situation, retrieval-augmented generation vs. fine-tuning is not even close — RAG wins clearly.
The most common and immediate application is AI for customer support automation. Support teams operate on dynamic data. Policies change. Products get updated. FAQs grow weekly. A RAG-powered chatbot pulls directly from your latest documents and knowledge base every single time a customer asks something. There is no outdated training data that leads to wrong answers. That reliability is what makes RAG the default choice for any business where accuracy has real consequences.
Four business environments where RAG clearly outperforms
Beyond support teams, RAG benefits for business show up consistently in four specific environments. Internal knowledge tools are one of the biggest. Employees do not need creativity from their AI — they need correct answers fast. AI help desk solutions built on RAG connect Slack, Notion, Confluence, company wikis, and databases into one reliable layer that surfaces verified answers with source citations. That transparency builds internal trust in a way that black-box fine-tuning cannot match.
For AI for ecommerce chatbots, RAG is practically non-negotiable. Pricing updates daily. Inventory changes by the hour. Return policies evolve seasonally. A chatbot built on RAG serves real-time product and policy data — not assumptions from a training set that is three months old. The same logic applies to AI in financial analytics. In finance, healthcare, and other regulated environments, hallucinations are not just annoying — they are dangerous. AI for compliance and regulation tools built on RAG grounds every response in verified reports and databases, which is exactly why these industries gravitate toward it so strongly.
RAG also gives you something fine-tuning cannot: source citations. When your AI shows exactly which document an answer came from, it becomes auditable, trustworthy, and far easier to defend in regulated or compliance-heavy environments.
How Combining RAG and LLMs Creates the Most Powerful AI Setup
Here is what the smartest engineering teams figured out early: you do not have to pick just one. Hybrid AI models that combine RAG with fine-tuned LLMs give you both depth and freshness. The fine-tuned model handles how the system reasons and speaks. RAG controls what it knows right now. Together, the result is an AI that is both fluent and factually grounded — a genuinely hard combination to beat.
In practice, a RAG and LLM combination works like this. When a user asks a question, the system first retrieves relevant facts or documents from your own data sources using vector embeddings and semantic search. Then the fine-tuned LLM uses that retrieved context to generate a response that is both accurate and on-brand. The retrieval handles currency and factual correctness. The LLM handles fluency and reasoning quality. Neither layer carries the whole weight alone.
When does a hybrid approach make financial sense?
The benefits of the AI hybrid architecture become most obvious when you are building for sales, support, compliance, finance, or consulting environments where both accuracy and communication quality genuinely matter. You do not need a finished product to go hybrid, but you do need two things: a real data source worth retrieving from, and a clear business problem that pure language models struggle to solve accurately on their own. Once you have those, a hybrid is not just possible — it is often the most logical and scalable next step for any enterprise AI solutions 2026 roadmap.
Fine-tuned LLM contributes
Consistent tone and brand voice, complex multi-step reasoning, structured output formats, predictable behavior at high volume.
RAG contributes
Real-time data accuracy, source citations, instant updates without retraining, and scalability as your document library grows.
Real-World Hybrid Examples That Actually Delivered Results
It is easy to talk about AI model comparison guides in the abstract. It is more useful to see what happened when real companies chose the hybrid path. Three examples stand out as particularly instructive for business leaders making this decision today.
LinkedIn — Customer Support AI
LinkedIn combined RAG with a knowledge graph for customer support. Instead of pure unstructured text retrieval, the system used structured connections between past support tickets. The result was a roughly 28–29% reduction in average per-issue resolution time in production — a tangible business.
Morgan Stanley — Financial Advisory Tools
Morgan Stanley’s internal AI suite combines OpenAI models with retrieval over the firm’s proprietary knowledge base. Financial advisors use it daily to pull detailed information from vast internal libraries — reducing research time significantly and improving the quality of client service. This is AI in financial analytics working exactly as it should at enterprise scale.
datums.ai — Business Intelligence Platform
Platforms like datums.ai explicitly combine retrieval workflows with advanced LLMs to turn raw business data into accurate, context-aware insights. By fetching relevant data before generating any AI response, the system delivers a meaningful boost in accuracy and relevance for AI-powered analytics tools in real-time business environments.
Three Questions to Ask Before You Commit to Any AI Model
Before you lock in a model architecture, slow down. This decision will live inside your product for years. The wrong choice does not just waste money — it creates compounding technical debt that grows harder to unwind over time. These three questions should shape every AI model selection for business conversation before a single line of code gets written.
What will this data look like in six months?
Your data will not stay still. Policies change. Products evolve. New documents appear constantly. Real-time AI data retrieval through RAG handles this without retraining. Fine-tuning alone struggles badly here. A hybrid setup lets you tune how the system thinks once, then continuously update what it knows — that combination keeps you current without a full redevelopment cycle every quarter.
Who owns model behavior when something goes wrong?
With fine-tuning, behavior is buried deep inside the model weights — hard to audit, harder to fix quickly. With RAG, answers are traceable back to specific source documents. A hybrid gives your product, data, and compliance teams shared, visible ownership. That matters enormously when a regulator asks how your AI reached a particular conclusion.
How easy is rollback if something breaks?
Pure fine-tuning is difficult to undo — you are essentially rebuilding the model. Pure RAG can feel limited in reasoning depth or tone control. Hybrid systems are modular by design. Swap a data source. Adjust a prompt. Roll back a change without taking the whole system offline. That operational flexibility is a genuine competitive advantage, especially for AI scalability for enterprises operating in fast-moving markets.
Working through these questions with experienced AI consulting services before you start building saves far more money than it costs. The teams that rush into a model commitment without asking them tend to find themselves rebuilding six months later — at two to three times the original budget. Whether you are a startup exploring AI tools or an enterprise team evaluating custom AI solutions for your business, getting the architecture right from the start is always the cheaper path.







